Machine learning has been a buzz word for quite some time now, and it hides everything from data analytics to neural networks under the hood. In this article we will uncover some of the workings of ML and I will show you a practical example of text classification — classifying movie ratings and text sentiment analysis.
Supervised and Unsupervised learning
ML has two main categories — supervised and unsupervised learning. In the first we have to have annotated data, for example temperature data along with its day and location. However, the typical example in the ML world is so called MNIST data-set — handwritten digits annotated with the actual numbers.
Classification and regression
Data classification serves a single purpose — to determine which class of data does the data point belong to (i.e. in the case of MNIST, determine the number handwritten in the image; in the case of the tutorial below the sentiment of a movie review). Regression is used for “predicting” and extrapolating from the data. For example generating text— you could generate a brand new Harry Potter chapter from the 7 books.
The second ML category is Unsupervised learning. It’s used for unannotated data, often used to find hidden patterns and connections among the data points, or for data clustering.
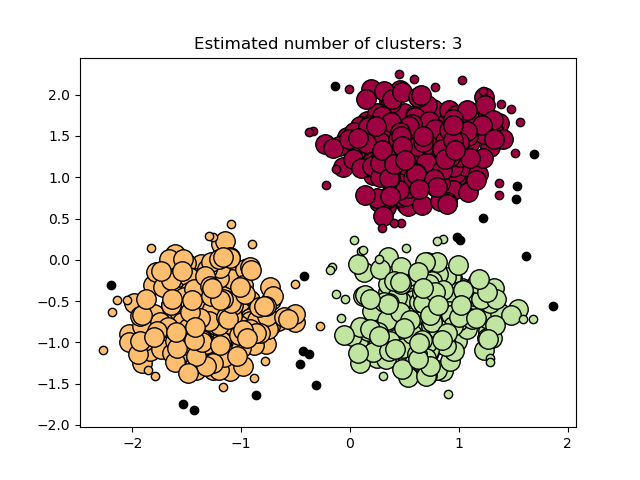 Unsupervised data clustering
Unsupervised data clustering
Data-sets
Data-sets have generally three parts — training, testing and validation set. Training set comprises of the main data, which ML algorithms use to “learn” about the problem, find patterns and data configurations and to find the optimal weight for each decision point. Validation set is a part of the training set, but at the same time it must differ from it. In other words — we randomly take i.e. 70% data for the training set and 30% for the validation set from one data-set. Testing set uses completely different data, preferably from a similar data-set. In the case of MNIST handwritten digits it would be the data from a different writer or writers. This way we can determine the accuracy of a classification model, the main metric used to measure the quality of the model. Sometimes you can find these two terms, testing and validation set, being freely interchanged, along with their proper meaning.
Now for the practical example
As an example I am going to show you how to make a movie text-review classifier.
First I’ve downloaded textual data from imdb.com. I’ve copied 20 positive reviews for the new movie “1917” and 20 negative reviews —the IMDB API would be used in a real life project of course. Also the reviews would not be saved in a text file, but in a .csv file and class-annotated. I use a basic format for ease of use for this tutorial — first 20 lines are positive, next 20 lines are negative.
 example of a data point from dataset.txt
I load the file in Python:
example of a data point from dataset.txt
I load the file in Python:
 All the lines are now loaded into a list. Now I have to transform the text in a way so the classifier can extract as much as useful information as it can during the training phase. I rid the text off special characters and perform lemmatization — converting the words into their root form:
All the lines are now loaded into a list. Now I have to transform the text in a way so the classifier can extract as much as useful information as it can during the training phase. I rid the text off special characters and perform lemmatization — converting the words into their root form:
 Now I need to convert the words into a format viable for the ML. Here comes vectorization into play. To vectorize a word means to transform it into a numerical form — one could say it is similar to finding the most used words in the text, but with far deeper context. The vectorization method I use is Bag of words, which does pretty much exactly that.
The vectorizer is set to take only the 20 most used words into the account; the words must occur at least 2 in the text and at most in 60% of the reviews (otherwise they would lose the information value and meaning, kind of like a the words of a neurotic guy who talks too much). On top of this I remove any stopwords, words without any important meaning for the ML (the, and, …).
Now I need to convert the words into a format viable for the ML. Here comes vectorization into play. To vectorize a word means to transform it into a numerical form — one could say it is similar to finding the most used words in the text, but with far deeper context. The vectorization method I use is Bag of words, which does pretty much exactly that.
The vectorizer is set to take only the 20 most used words into the account; the words must occur at least 2 in the text and at most in 60% of the reviews (otherwise they would lose the information value and meaning, kind of like a the words of a neurotic guy who talks too much). On top of this I remove any stopwords, words without any important meaning for the ML (the, and, …).
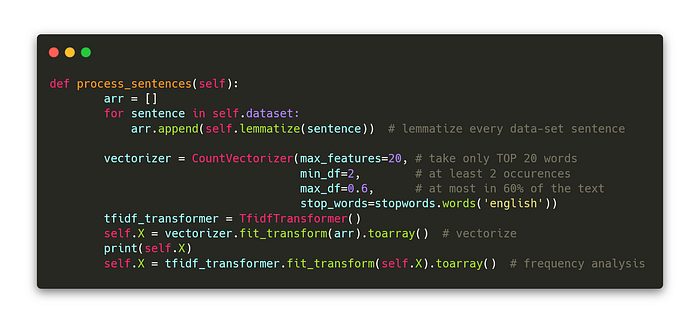 Now the text is transformed into numerical values it looks like this (every row is a single review):
Now the text is transformed into numerical values it looks like this (every row is a single review):
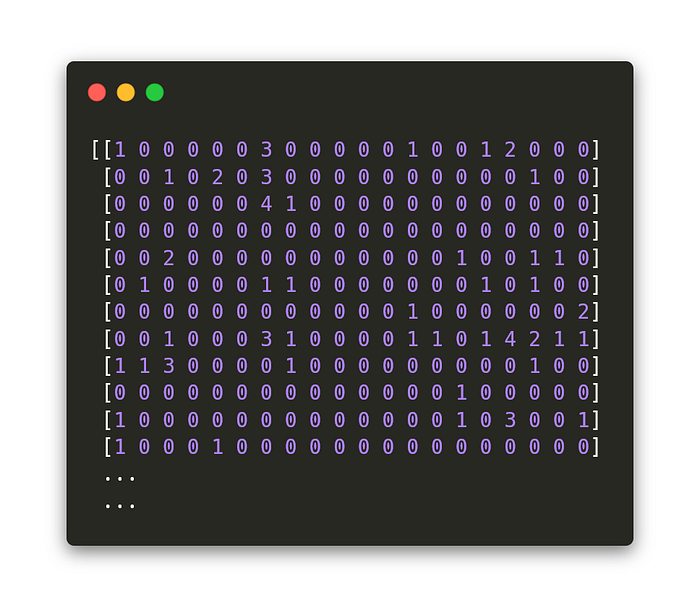
Classifier training
I am using a simple classifier, K-nearest neighbors with 5 neighbors and the 70/30 data-set split.
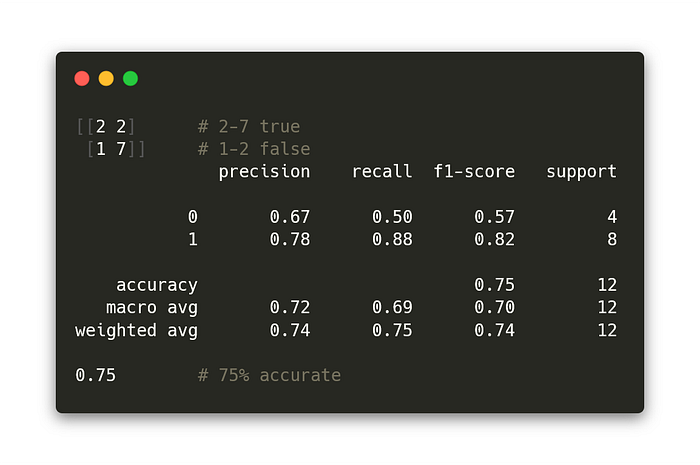
 I print the classification report, confusion matrix and model accuracy at the end. Confusion matrix shows the true positives and true negatives on the diagonal, and false positives and false negatives on the other diagonal. I get 2–7 true ratio for this model, with these settings and for this small data-set. The accuracy went up to 75%, but that is kind of rare for a data-set this small (the accuracy would fall down to 35% based on the model settings). With more data (thousands of data points more) and a more intelligent classifier the accuracy would probably go over 90% without any problems.
I print the classification report, confusion matrix and model accuracy at the end. Confusion matrix shows the true positives and true negatives on the diagonal, and false positives and false negatives on the other diagonal. I get 2–7 true ratio for this model, with these settings and for this small data-set. The accuracy went up to 75%, but that is kind of rare for a data-set this small (the accuracy would fall down to 35% based on the model settings). With more data (thousands of data points more) and a more intelligent classifier the accuracy would probably go over 90% without any problems.
Sentiment analysis in text
I will show you one more interesting experiment — text sentiment analysis. It is a kind of a NLP (natural language processing) for opinion and sentiment extraction. Social networks are commonly used both as source for the data and as a target for classification models (Facebook and its creepy big brother analysis of your private chats, wall feeds etc.).
I use a fairly simple example here, VADER (Valence Aware Dictionary and sEntiment Reasoner) for on of the movie reviews. VADER classifies the text-sentiment based on a pre-trained classification model (there are more sophisticated methods for a more accurate and reliable analysis like Google Cloud Natural Language API).
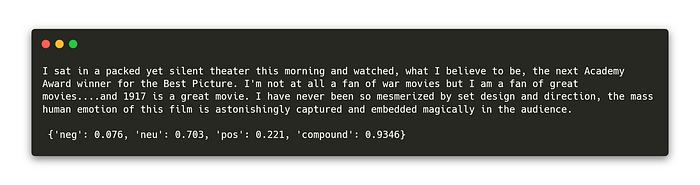
 The 3 lines of code above find 70% neutral sentiment and 22% positive sentiment in the text (it’s one of the positive reviews):
The 3 lines of code above find 70% neutral sentiment and 22% positive sentiment in the text (it’s one of the positive reviews):
Before you go
So, I hope you’ve enjoyed this article and the tutorial and if you are interested in the complete source code (with imports and other details), you can find it on my github. See you next time!
